The five layers
The Lyzr stack has five layers. The top three (Agent Framework, Agent Studio, and Architect) are where you build and run agents. They sit on two foundation layers that every agent depends on.
Layer 1: Agent Framework
The foundation. The Lyzr Agent Framework is the runtime engine that every agent runs on top of, whether the agent was built in Agent Studio, via the ADK, or through the API. It handles:- LLM calls (model-agnostic: OpenAI, Anthropic, Google, Bedrock, Groq, Perplexity)
- Tool execution and function calling
- Memory management (short-term, long-term, Cognis)
- Safe and Responsible AI enforcement, embedded into the inference loop
- Protocol adapters: MCP, OpenAI functions, Google A2A, REST, gRPC
- ADK (Agent Development Kit): A Python/TypeScript SDK for building and managing agents in code. Use the ADK when you need fine-grained control, CI/CD pipelines, or integration into an existing codebase.
- REST API: Direct HTTP access to all framework capabilities from any language or stack.
Layer 2: Agent Studio
The builder layer. A web-based visual environment for:- Creating and configuring agents (role, goal, instructions, model, tools, memory, Knowledge Base)
- Multi-agent orchestration (Manager Agent for dynamic workflows, SuperFlow for DAG-based workflows)
- Knowledge base management (Classic Knowledge Base, Knowledge Graph, Semantic Model)
- Voice agents with telephony integrations
- Evaluation, versioning, and deployment
- Team governance (roles, audit log)
Layer 3: Architect
The application layer. A text-to-app platform that sits above Agent Studio. You describe the product you want in plain English, and Architect generates a full-stack agentic application (frontend, multi-agent backend, auth, and database) automatically. Architect uses the Studio agents you’ve already configured and connects them into complete applications without requiring manual wiring. Use Architect for prototyping AI-powered apps in minutes, building customer-facing tools without writing frontend code, or orchestrating multiple agents into an end-to-end product experience.Layer 4: Model layer
The model layer is model-agnostic. Agents can run on different LLM providers (OpenAI, Anthropic, Google, Amazon Bedrock, Groq, Perplexity, or a model you bring yourself) and you can swap models at any time without changing your integration.Layer 5: Infrastructure layer
The infrastructure layer is cloud-agnostic and provides the secure runtime. The same stack deploys to Lyzr Cloud, your own cloud, or on-premise without code changes.How data flows through an agent call
Every request that reaches a Lyzr agent passes through a consistent processing pipeline. Safe and Responsible AI checks run on input before the agent executes, and again on output before the response is returned.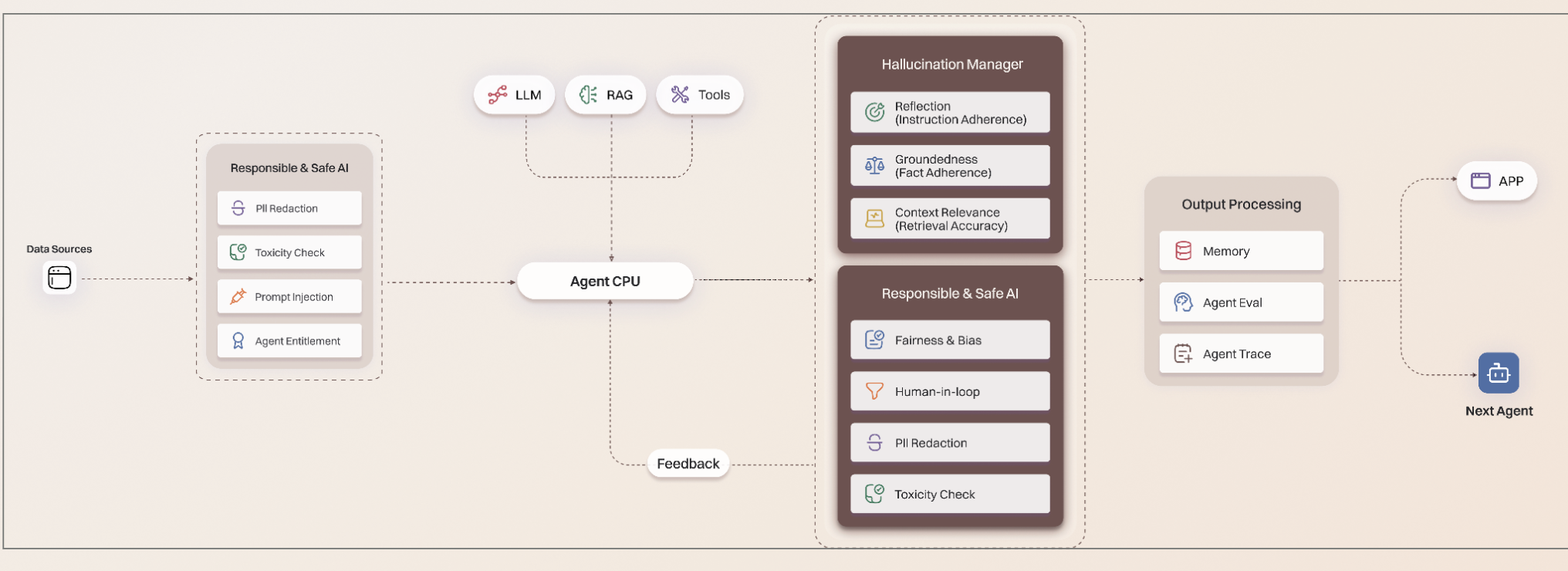 The pipeline in detail:
Input processing: When a request arrives, the Responsible and Safe AI module checks the input for PII, prompt injection attempts, toxicity, and agent entitlement before passing it to the Agent CPU.
Agent CPU: The core execution engine. It runs LLM inference, retrieves context from the Knowledge Base (RAG), and executes any tool calls the LLM requests. A feedback loop allows the agent to refine its answer based on intermediate results.
Output processing (Hallucination Manager): Before the response is returned, the Hallucination Manager runs three checks: Reflection (instruction adherence), Groundedness (fact adherence against retrieved sources), and Context Relevance (retrieval accuracy).
Output processing (Responsible and Safe AI): A second pass checks the output for fairness and bias, applies Human-in-loop gates where configured, and re-checks for PII and toxicity.
Final output: The processed response is written to Memory, logged to Agent Trace, scored by Agent Eval if configured, and returned to the calling application or forwarded to the next agent in a multi-agent workflow.
The pipeline in detail:
Input processing: When a request arrives, the Responsible and Safe AI module checks the input for PII, prompt injection attempts, toxicity, and agent entitlement before passing it to the Agent CPU.
Agent CPU: The core execution engine. It runs LLM inference, retrieves context from the Knowledge Base (RAG), and executes any tool calls the LLM requests. A feedback loop allows the agent to refine its answer based on intermediate results.
Output processing (Hallucination Manager): Before the response is returned, the Hallucination Manager runs three checks: Reflection (instruction adherence), Groundedness (fact adherence against retrieved sources), and Context Relevance (retrieval accuracy).
Output processing (Responsible and Safe AI): A second pass checks the output for fairness and bias, applies Human-in-loop gates where configured, and re-checks for PII and toxicity.
Final output: The processed response is written to Memory, logged to Agent Trace, scored by Agent Eval if configured, and returned to the calling application or forwarded to the next agent in a multi-agent workflow.